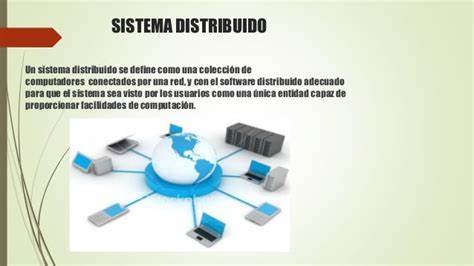
Sistema distribuido
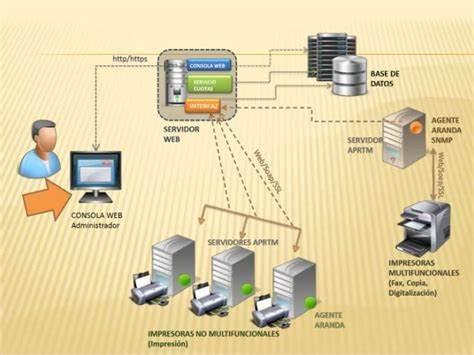
La computación distribuida es un modelo para resolver problemas de computación masiva utilizando un gran número de ordenadores organizados en clústeres incrustados en una infraestructura de telecomunicaciones distribuida.
La computación distribuida es un modelo informático que permite hacer grandes cálculos utilizando miles de ordenadores de voluntarios. Este sistema se basa en repartir la información a través de Internet mediante un software, previamente descargado por el usuario, a diferentes ordenadores, que van resolviendo los cálculos y una vez tienen el resultado lo envían al servidor. Este proyecto, casi siempre solidarios, reparten la información a procesar entre los miles de ordenadores voluntarios para poder alcanzar cuotas de procesamiento a menudo mayores que las de superordenadores.
El beneficio de la computación distribuido es que la actividad de procesamiento se puede asignar a la ubicación o ubicaciones donde sea posible, realizarlo con más eficiencia. Podemos tomar como ejemplo la computación distribuida en una empresa, cada oficina puede organizar y manipular los datos para satisfacer necesidades específicas, así como compartir el producto con el resto de la organización. También nos permite optimización de los equipos y mejora el balanceo del procesamiento dentro de una aplicación, este último es de gran importancia ya que en algunas aplicaciones simplemente, no hay una máquina que sea capaz de realizar todo el procesamiento.
Para ello se puede hablar de "procesos". Un proceso realiza dos tipos de operaciones:
•Declaración Inicial y las Solicitudes Externas realizadas por otros procesos. éstas operaciones se ejecutan una a la vez intercalándose entre sí. Esto continúa hasta que la declaración termina o espera que una condición se convierta en realidad.
•Luego se inicia otra operación (como resultado de una solicitud externa). Cuando esta operación, a su vez, termina o espera, el proceso comenzará otra operación (volver a cuestionado por otro proceso) o reanudará una operación anterior (como resultado de que una condición se convierta en verdadera).
•Este entrelazado de la declaración inicial y las solicitudes externas continúa para siempre. Si la declaración inicial termina, el proceso continúa existiendo, a pesar de que el primer proceso termine, continuará aceptando solicitudes Externas
Desde el inicio de la era de la computadora moderna (1945), hasta cerca de 1985, solo se conocía la computación centralizada. A partir de la mitad de la década de los ochenta aparecen dos avances tecnológicos fundamentales:
Aparecen los sistemas distribuidos, en contraste con los sistemas centralizados.
Un sistema distribuido es un sistema en el que los componentes hardware o software se encuentran en computadores unidos mediante una red.
Los S. O. para sistemas distribuidos han tenido importantes desarrollos, pero todavía existe un largo camino por recorrer.
Los usuarios pueden acceder a una gran variedad de recursos computacionales:
Características de un sistema distribuido:
El concepto de transmisión de mensajes se originó a finales de la década de los 60. A pesar de que el multiprocesador de propósito general y las redes de computadoras no existían en ese momento, surgió la idea de organizar un sistema operativo como una colección de procesos de comunicación donde cada proceso tiene una función específica, en la cual, no pueden interferir otros (variables no compartidas). De esta forma, en los años 70 nacieron los primeros sistemas distribuidos generalizados, las redes de área local (LAN) como Ethernet.
Este suceso generó inmediatamente una gran cantidad de lenguajes, algoritmos y aplicaciones, pero no fue hasta que los precios de las LANs bajaron, cuando se desarrolló la computación cliente-servidor. A finales de la década de 1960 se creó ‘Advanced Research Projects Agency Network’ (ARPANET). Esta agencia fue la espina dorsal de Internet hasta 1990, tras finalizar la transición al protocolo TCP/IP, iniciada en 1983. En los primeros años de 1970, nace el correo electrónico ARPANET, el que es considerado como la primera aplicación distribuida a gran escala.
Durante las dos últimas décadas se han realizado investigaciones en materia de algoritmos distribuidos y se ha avanzado considerablemente en la madurez del campo, especialmente durante los años ochenta. Originalmente la investigación estaba muy orientada hacia aplicaciones de los algoritmos en redes de área amplia (WAN), pero hoy en día se han desarrollado modelos matemáticos que permiten la aplicación de los resultados y métodos a clases más amplias de entornos distribuidos.
Existen varias revistas y conferencias anuales que se especializan en los resultados relativos a los algoritmos distribuidos y la computación distribuida. La primera conferencia sobre la materia fue el simposio ‘Principles of Distributed Computing’ (PoDC) en 1982, cuyos procedimientos son publicados por ‘Association for Computing Machinery, Inc’. ‘International Workshops on Distributed Algorithms’ (WDAG) se celebró por primera vez en Ottawa en 1985 y después en Ámsterdam (1987) y Niza (1989). Desde entonces, sus actas son publicadas por Springer-Verlag en la serie ‘Lecture Notes on Computer Science’. En 1998, el nombre de esta conferencia cambió a Distributed Computing (DISC). Los simposios anuales sobre teoría de computación (‘SToC’) y fundamentos de informática (FoCS) cubren toda las áreas fundamentales de la informática, llevando a menudo documentos sobre computación distribuida. Las actas de ‘SToC’ son publicadas por ‘Association for Computing Machinery, Inc.’ y los de FoCS por el IEEE. ‘The Journal of Parallel and Distributed Computing (JPDC), ‘Distributed Computing’ e ‘Information Processing Letters’ (IPL) publican algoritmos distribuidos regularmente.
Así fue como nacieron los sistemas distribuidos. .

Al igual que ocurre con los sistemas distribuidos, en los sistemas paralelos no existe una definición clara. Lo único evidente es que cualquier sistema en el que los eventos puedan ordenarse de manera parcial se consideraría un sistema paralelo y por lo tanto, esto incluiría a todos los sistemas distribuidos y sistemas de memoria compartida con múltiples hilos de control. De esta forma, se podría decir que los sistemas distribuidos forman una subclase de sistemas paralelos, donde los espacios de estado de los procesos no se superponen.
Algunos distinguen los sistemas paralelos de los sistemas distribuidos en función de sus objetivos: los sistemas paralelos se centran en el aumento del rendimiento, mientras que los sistemas distribuidos se centran en la tolerancia de fallos parciales.
Desde otro punto de vista, en la computación paralela, todos los procesadores pueden tener acceso a una memoria compartida para intercambiar información entre ellos y en la computación distribuida, cada procesador tiene su propia memoria privada, donde la información se intercambia pasando mensajes entre los procesadores.
Luego se podría decir que la computación en paralelo es una forma particular de computación distribuida fuertemente acoplada, y la computación distribuida una forma de computación paralela débilmente acoplada.
La figura que se encuentra a la derecha ilustra la diferencia entre los sistemas distribuidos y paralelos. La figura a. es un esquema de un sistema distribuido, el cual se representa como una topología de red en la que cada nodo es una computadora y cada línea que conecta los nodos es un enlace de comunicación. En la figura b) se muestra el mismo sistema distribuido con más detalle: cada computadora tiene su propia memoria local, y la información solo puede intercambiarse pasando mensajes de un nodo a otro utilizando los enlaces de comunicación disponibles. En la figura c) se muestra un sistema paralelo en el que cada procesador tiene acceso directo a una memoria compartida.
Hay numerosos ejemplos de sistemas distribuidos que se utilizan en la vida cotidiana en una variedad de aplicaciones. La mayoría de los sistemas están estructurados como sistemas cliente-servidor, en los que la máquina servidora es la que almacena los datos o recursos, y proporcionan servicio a varios clientes distribuidos geográficamente. Sin embargo, algunas aplicaciones no dependen de un servidor central, es decir, son sistemas peer-to-peer, cuya popularidad va en aumento. Presentamos aquí algunos ejemplos de sistemas distribuidos:
Los sistemas destinados a ser utilizados en entornos del mundo real deben estar diseñados para funcionar correctamente en la gama más amplia posible de circunstancias y ante posibles dificultades y amenazas. Las propiedades y los problemas de diseño de sistemas distribuidos pueden ser capturados y discutidos mediante el uso de modelos descriptivos. Cada modelo tiene la intención de proporcionar una descripción abstracta y simplificada pero consistente de un aspecto relevante del diseño del sistema distribuido.
Algunos aspectos relevantes pueden ser: el tipo de nodo y de red, el número de nodos y la responsabilidad de estos y posibles fallos tanto en la comunicación como entre los nodos. Se pueden definir tantos modelos como características queramos considerar en el sistema, pero se suele atender a esta clasificación:
Representan la forma más explícita para describir un sistema, identifican la composición física del sistema en términos computacionales, principalmente atendiendo a heterogeneidad y escala. Podemos identificar tres generaciones de sistemas distribuidos:
El objetivo general de este tipo de modelo es garantizar el reparto de responsabilidades entre componentes del sistema distribuido y la ubicación de dichos componentes. Las principales preocupaciones son determinar la relación entre procesos y hacer al sistema confiable, adaptable y rentable.
Arquitectura de Capas: permite aprovechar el concepto de abstracción, en este modelo, un sistema complejo se divide en un número arbitrario de capas, donde las capas superiores hacen uso de los servicios proporcionados por las capas inferiores. De esta forma una capa ofrece un servicio sin que las capas superiores o inferiores estén al tanto de los detalles de implementación. Un servicio distribuido puede ser proporcionado por uno o más procesos del servidor, que interactúan entre sí y con los procesos de cliente para mantener una visión de todo el sistema. La organización de los servicios en capas se da debido a la complejidad de los sistemas distribuidos.
Una estructura común del modelo de arquitectura de capas se divide en cuatro capas: la capa de aplicaciones y servicios, la capa de middleware, la capa de sistema operativo y la capa de hardware de redes y computadoras.
La plataforma para sistemas y aplicaciones distribuidas se compone de las capas de hardware y software de nivel más bajo, esto incluye el hardware de red, las computadoras y el sistema operativo del sistema distribuido. Esta capa proporciona servicios a las capas superiores, las cuales se implementan de forma independiente en cada equipo.
El middleware es todo el software que tiene como finalidad enmascarar el sistema distribuido, proporcionando una apariencia homogénea del sistema.
La capa superior, destinada a aplicaciones y servicios son las funcionalidades proporcionadas a los usuarios, estas se conocen como aplicaciones distribuidas.
Todos los modelos anteriores comparten un diseño y un conjunto de requisitos necesarios para proporcionar confiabilidad y seguridad a los recursos del sistema. Un modelo fundamental toma una perspectiva abstracta, de acuerdo al análisis de aspectos individuales del sistema distribuido; debe contener solo lo esencial a tener en cuenta para comprender y razonar sobre algunos aspectos de un comportamiento del sistema.
Por lo tanto, para que pueda afirmarse que existe una comunicación fiable entre dos procesos debe asegurarse su integridad y su validez.

Cuando hablamos de modelos en un sistema distribuido, nos referimos principalmente al hecho de automatizar tareas, usando un computador, del tipo pregunta-respuesta, es decir, que cuando realicemos una pregunta al computador, este nos debe contestar con una respuesta apropiada. En la informática teórica, este proceso se conoce como problemas computacionales.
Formalmente, un problema computacional consiste en instancias junto con una solución a cada una de ellas. Las instancias se pueden traducir como preguntas que nosotros hacemos al computador y las soluciones como las respuestas del mismo a nuestras preguntas.
Teóricamente, la informática teórica busca encontrar la relación entre problemas que puedan resolverse mediante un computador (teoría de la computabilidad) y la eficiencia al realizarlo(teoría de la complejidad computacional).
Comúnmente, hay tres puntos de vista:
Un algoritmo paralelo define múltiples operaciones para ser ejecutadas en cada paso. Esto incluye comunicación/coordinación entre las unidades de procesamiento.
Un ejemplo claro para este tipo de modelos sería el modelo de máquinas de acceso aleatorio paralelo (PRAM).

Detalles del modelo PRAM
Hay mucha más información acerca de este tipo de algoritmo de una forma más resumida en los siguientes libros.
Ambiente geográficamente distribuido: En primer lugar, en muchas situaciones, el entorno informático en sí mismo está geográficamente distribuido. Como ejemplo, consideremos una red bancaria. Se supone que cada banco debe mantener las cuentas de sus clientes. Además, los bancos se comunican entre sí para monitorear las transacciones interbancarias, o registrar las transferencias de fondos de los cajeros automáticos geográficamente dispersos. Otro ejemplo común de un entorno informático geográficamente distribuido es la Internet, que ha influido profundamente en nuestra forma de vida. La movilidad de los usuarios ha añadido una nueva dimensión a la distribución geográfica.
Speed up: En segundo lugar, existe la necesidad de acelerar los cálculos. La velocidad de cómputo en los uniprocesadores tradicionales se está acercando rápidamente al límite físico. Mientras que los procesadores superescalares y VLIW estiran el límite introduciendo un paralelismo a nivel arquitectónico (cuestión de la instrucción), las técnicas no se escalan mucho más allá de un cierto nivel. Una técnica alternativa para obtener más potencia de cálculo es utilizar procesadores múltiples. Dividir un problema entero en subproblemas más pequeños y asignar estos subproblemas a procesadores físicos separados que puedan funcionar simultáneamente es un método potencialmente atractivo para aumentar la velocidad de cálculo. Además, este enfoque promueve una mejor escalabilidad, en la que los usuarios pueden aumentar progresivamente la potencia de cálculo adquiriendo elementos o recursos de procesamiento adicionales. A menudo, esto es más sencillo y económico que invertir en un único uniprocesador superrápido.
Compartir recursos: En tercer lugar, existe la necesidad de compartir los recursos. El usuario de la computadora A puede querer usar una impresora láser conectada con la computadora B, o el usuario de la computadora B puede necesitar un poco de espacio extra en el disco disponible en la computadora C para almacenar un archivo grande. En una red de estaciones de trabajo, es posible que la estación de trabajo A quiera utilizar la potencia de cálculo en reposo de las estaciones de trabajo B y C para aumentar la velocidad de un determinado cálculo. Las bases de datos distribuidas son buenos ejemplos del intercambio de recursos de software, en los que una gran base de datos puede almacenarse en varias máquinas anfitrionas y actualizarse o recuperarse sistemáticamente mediante una serie de procesos de agentes.

Tolerancia a fallos: Por último, los poderosos uniprocesadores, o sistemas de computación construidos alrededor de un solo nodo central son propensos a un completo colapso cuando el procesador falla. Muchos usuarios consideran que esto es arriesgado. Sin embargo, están dispuestos a transigir con una degradación parcial del rendimiento del sistema, cuando un fallo paraliza una fracción de los muchos elementos de procesamiento o enlaces de un sistema distribuido. Esta es la esencia de la degradación gradual. La otra cara de este enfoque es que, al incorporar elementos de procesamiento redundantes en un sistema distribuido, se puede aumentar potencialmente la fiabilidad o la disponibilidad del sistema. Por ejemplo, en un sistema que tiene triple redundancia modular (TMR), se utilizan tres unidades funcionales idénticas para realizar el mismo cómputo, y el resultado correcto se determina por mayoría de votos. En otros sistemas distribuidos tolerantes de fallos, los procesadores se comprueban mutuamente en puntos de control predefinidos, lo que permite la detección automática de fallos, el diagnóstico y la eventual recuperación. Así pues, un sistema distribuido ofrece una excelente oportunidad para incorporar la tolerancia a fallos y la degradación grácil.
Modularidad: La arquitectura cliente/servidor está construida sobre la base de módulos conectables. Tanto el cliente como el servidor son módulos del sistema independientes uno del otro y pueden ser reemplazados sin afectarse mutuamente. Se agregan funciones al sistema ya sea creando nuevos módulos o mejorando los existentes.
Portabilidad: Actualmente el poder de procesamiento se puede encontrar en varios tamaños: super servidores, servidores, desktop, notebooks, máquinas portátiles. Las soluciones con computación distribuida permiten a las aplicaciones estar localizadas donde resulte más ventajoso u óptimo.
Escalabilidad: El sistema debe diseñarse de tal manera que la capacidad pueda ser aumentada con la creciente demanda del sistema.
Heterogeneidad: La infraestructura de comunicaciones consiste en canales de diferentes capacidades.
Gestión de los recursos: En los sistemas distribuidos, los recursos se encuentran en diferentes lugares. El enrutamiento es un problema en la capa de red y en la capa de aplicación.
Seguridad y privacidad: Dado que los sistemas distribuidos tratan con datos e información sensible, se deben tener fuertes medidas de seguridad y privacidad. La protección de los activos del sistema distribuido así como los compuestos de nivel superior de estos recursos son cuestiones importantes en el sistema distribuido.
Transparencia: La transparencia significa hasta qué punto el sistema distribuido debe aparecer para el usuario como un sistema único. El sistema distribuido debe ser diseñado para ocultar en mayor medida la complejidad del sistema.
Apertura: La apertura significa hasta qué punto un sistema es diseñado utilizando protocolos estándar para apoyar la interoperabilidad. Para lograr esto, el sistema distribuido debe tener interfaces bien definidas.
Sincronización: Uno de los principales problemas es la sincronización de los cálculos consistentes en miles de componentes. Métodos actuales de sincronización como los semáforos, los monitores, las barreras, la llamada a procedimientos remotos, la invocación de métodos de objetos y el paso de mensajes, no escalan bien.
Interbloqueo y condiciones de carrera: El interbloqueo y las condiciones de carrera son otras grandes cuestiones en el sistema distribuido, especialmente en el contexto de las pruebas. Se convierte en un tema más importante especialmente en el entorno de multiprocesadores de memoria compartida.
Escribe un comentario o lo que quieras sobre Sistema distribuido (directo, no tienes que registrarte)
Comentarios
(de más nuevos a más antiguos)
Aún no hay comentarios, ¡deja el primero!