Regresión lineal
En estadística, la regresión lineal o ajuste lineal es un modelo matemático usado para aproximar la relación de dependencia entre una variable dependiente , variables independientes con y un término aleatorio . Este método es aplicable en muchas situaciones en las que se estudia la relación entre dos o más variables o predecir un comportamiento, algunas incluso sin relación con la tecnología. En caso de que no se pueda aplicar un modelo de regresión a un estudio, se dice que no hay correlación entre las variables estudiadas. Este modelo puede ser expresado como:





donde:
el término es la intersección o término "constante", las son los parámetros respectivos a cada variable independiente, y es el número de parámetros independientes a tener en cuenta en la regresión. La regresión lineal puede ser contrastada con la regresión no lineal.


La primera forma de regresión lineal documentada fue el método de los mínimos cuadrados que fue publicada por Legendre en 1805, Gauss publicó un trabajo en donde desarrollaba de manera más profunda el método de los mínimos cuadrados, y en dónde se incluía una versión del teorema de Gauss-Márkov.
El término regresión se utilizó por primera vez en el estudio de variables antropométricas: al comparar la estatura de padres e hijos, donde resultó que los hijos cuyos padres tenían una estatura muy superior al valor medio, tendían a igualarse a este, mientras que aquellos cuyos padres eran muy bajos tendían a reducir su diferencia respecto a la estatura media; es decir, "regresaban" al promedio. La constatación empírica de esta propiedad se vio reforzada más tarde con la justificación teórica de ese fenómeno.
El término lineal se emplea para distinguirlo del resto de técnicas de regresión, que emplean modelos basados en cualquier clase de función matemática. Los modelos lineales son una explicación simplificada de la realidad, mucho más ágiles y con un soporte teórico mucho más extenso por parte de la matemática y la estadística.
Pero bien, como se ha dicho, se puede usar el término lineal para distinguir modelos basados en cualquier clase de aplicación.
El modelo de regresión lineal será aplicado en aquellos casos en los que la variable independiente Y sea continua. El modelo lineal relaciona la variable dependiente con variables regresoras con o cualquier transformación de éstas que generen un hiperplano de parámetros desconocidos:



donde es una variable aleatoria que recoge todos aquellos factores de la realidad no controlables u observables y que por tanto se asocian con el azar, y es la que confiere al modelo su carácter estocástico. En el caso más sencillo, con una sola variable explícita, el hiperplano es una recta:
El problema de la regresión consiste en elegir unos valores determinados para los parámetros desconocidos , de modo que la ecuación quede completamente especificada. Para ello se necesita un conjunto de observaciones o una muestra proveniente de este modelo. En una observación -ésima cualquiera, se registra el comportamiento simultáneo de la variable dependiente y las variables explícitas (las perturbaciones aleatorias se suponen no observables).



Los valores escogidos como estimadores de los parámetros , son los coeficientes de regresión sin que se pueda garantizar que coincidan con parámetros reales del proceso generador. Por tanto, en

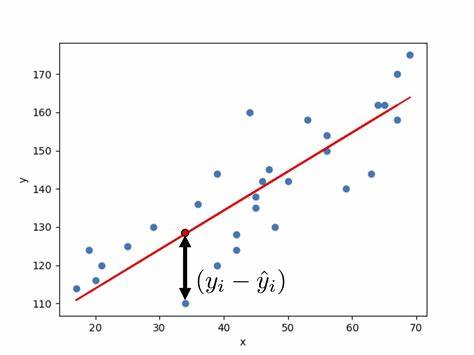
Los valores son por su parte estimaciones o errores de la perturbación aleatoria. Ei es el residuo e indica la bondad del ajuste realizado para cada punto. Se calcula de la siguiente forma:

Una vez se ha obtenido la recta de regresión, es necesario comprobar la bondad del ajuste realizado mediante el siguiente análisis ANOVA:

n= número de datos. Se compara F0 con valor F crítico (tabla F de Scnedecor) con valor de significación α, 1, y n-2 grados de libertad concluyendo: Si F0< Ft, el modelo es apropiado, Si F0> Ft, el modelo utilizado no es apropiado.
Existen diferentes tipos de regresión lineal que se clasifican de acuerdo a sus parámetros:
El modelo de regresión lineal simple sólo está conformado por dos variables estadísticas llamadas y . Considera una única variable independiente o explicativa, , y una variable dependiente o respuesta, , asumiendo que la relación entre ambas es lineal. Para la regresión lineal simple, se asume que y se relacionan mediante la relación funcional (siendo β1 y β0 estimadores):

donde son constantes desconocidas llamadas coeficientes de regresión. β1: Se trata del cociente entre la interacción obtenida entre ambas variables y la suma de cuadrados de los valores de la variable dependiente. Este valor corresponde a la pendiente de la recta. Por su parte, β0 es el resultado de la siguiente ecuación en la que aparecen los valores medios correspondientes a ambas variables y el estimador β1 obtenido anteriormente. Este valor es la ordenada en el origen.

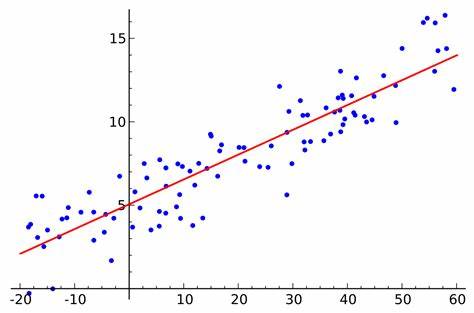
Dado que los parámetros y son constantes desconocidas, estas deben estimarse mediante los datos de la muestra, supóngase que se tiene datos , se estimarán los parámetros utilizando el método de mínimos cuadrados.



Se estiman y tal que la suma de los cuadrados de las diferencias entre las observaciones y la recta de regresión sea mínima, esto es, buscamos minimizar la función error cuadrático dada por

La función de error cuadrático alcanza un mínimo en el punto tal que


entonces derivando respecto a y , evaluando en y e igualando a cero, obtenemos el siguiente sistema de ecuaciones


estas dos ecuaciones son conocidas como ecuaciones normales la solución de dicho sistema de ecuaciones está dada por:
La interpretación del parámetro medio es que un incremento en Xi de una unidad, Yi incrementará en . Luego el modelo ajustado de regresión lineal simple es

Para los casos en los que un modelo lineal no sea el más adecuado, se pueden aplicar los llamados modelos intrínsecamente lineales que transforman la recta en otro tipo de función. Un ejemplo sería la función exponencial:

La regresión lineal permite analizar la relación entre dos o más variables a través de ecuaciones, lo que se denomina regresión múltiple o regresión lineal múltiple.
Constantemente en la práctica de la investigación estadística, se encuentran variables que de alguna manera están relacionadas entre sí, por lo que es posible que una de las variables puedan relacionarse matemáticamente en función de otra u otras variables.
Este modelo cuenta con varias variables regresoras, por lo que cuenta con varios parámetros, para la regresión lineal múltiple, se asume que la variable de respuesta se relaciona con las variables regresoras mediante la relación funcional:

donde los parámetros son llamados coeficientes del modelo de regresión múltiple.

Supongamos que se tiene una muestra de tamaño dada por con donde denota el -ésimo valor observado en el regresor y denota la -ésima observación de entonces el modelo toma la forma


donde es el error asociado a la -ésima medición del valor y sigue los supuestos usuales de modo que (media cero, varianza constante e igual a y con ).





Para estimar los parámetros del modelo, se puede utilizar el método de mínimos cuadrados, en este caso, la función de error cuadrático está dada por
la cual deseamos minimizar.
Los estimadores por mínimos cuadrados denotados por deben satisfacer

para . Resolver este sistema con ecuaciones de forma analítica es complicado por lo que se recurre a escribir el modelo de regresión lineal múltiple


en forma matricial como
siendo
donde y .


En forma matricial, la función de error cuadrático puede ser escrita como
La obtención de los estimadores se realizará resolviendo el sistema lineal de ecuaciones. Los estimadores por mínimos cuadrados deben satisfacer
donde denota el vector que contiene a los estimadores y denota un vector con ceros.


Puede verificarse que la condición anterior se reduce a
Si la matriz inversa existe entonces el estimador por mínimos cuadrados está dado por

Por lo que el modelo ajustado de regresión está dado por
Al igual que en el caso anterior será necesario efectuar una comprobación de la bondad de ajuste mediante un test ANOVA.

k= número de variables. n= número de datos. p= número de grupos. Siendo estas las expresiones para el cálculo de las sumas de cuadrados:

Con el valor F crítico (valor de significación α, k, y n-p grados de libertad) correspondiente y se compara con F0 determinando la bondad del ajuste de la misma forma que en el caso de una variable.
Las rectas de regresión son las rectas que mejor se ajustan a la nube de puntos (o también llamado diagrama de dispersión) generada por una distribución conjunta. Matemáticamente, son posibles dos rectas de máximo ajuste:
La correlación ("r") de las rectas determinará la calidad del ajuste. Si r es cercano o igual a 1, el ajuste será bueno y las predicciones realizadas a partir del modelo obtenido serán muy fiables (el modelo obtenido resulta verdaderamente representativo); si r es cercano o igual a 0, se tratará de un ajuste malo en el que las predicciones que se realicen a partir del modelo obtenido no serán fiables (el modelo obtenido no resulta representativo de la realidad). Ambas rectas de regresión se intersecan en un punto llamado centro de gravedad de la distribución.
El modelo de regresión lineal es aplicado en un gran número de campos, desde el ámbito científico hasta el ámbito social, pasando por aplicaciones industriales ya que en multitud de situaciones se encuentran comportamientos lineales. Estos son algunos ejemplos aplicados a diversos campos:
Una línea de tendencia representa una tendencia en una serie de datos obtenidos a través de un largo período. Este tipo de líneas puede decirnos si un conjunto de datos en particular (como por ejemplo, el PIB, el precio del petróleo o el valor de las acciones) han aumentado o decrementado en un determinado período. Se puede dibujar una línea de tendencia a simple vista fácilmente a partir de un grupo de puntos, pero su posición y pendiente se calcula de manera más precisa utilizando técnicas estadísticas como las regresiones lineales. Las líneas de tendencia son generalmente líneas rectas, aunque algunas variaciones utilizan polinomios de mayor grado dependiendo de la curvatura deseada en la línea.
En medicina, las primeras evidencias relacionando la mortalidad con el fumar tabaco vinieron de estudios que utilizaban la regresión lineal. Los investigadores incluyen una gran cantidad de variables en su análisis de regresión en un esfuerzo por eliminar factores que pudieran producir correlaciones espurias.
En el caso del tabaquismo, los investigadores incluyeron el estado socioeconómico para asegurarse que los efectos de mortalidad por tabaquismo no sean un efecto de su educación o posición económica. No obstante, es imposible incluir todas las variables posibles en un estudio de regresión. En el ejemplo del tabaquismo, un hipotético gen podría aumentar la mortalidad y aumentar la propensión a adquirir enfermedades relacionadas con el consumo de tabaco. Por esta razón, en la actualidad las pruebas controladas aleatorias son consideradas mucho más confiables que los análisis de regresión.
La concentración de un elemento es uno de los parámetros de mayor importancia en los procesos químicos aplicados en la industria. Esta cuantificación se puede obtener mediante un espectrofotómetro, dispositivo que requiere se calibrado. Para ello se elabora una recta de calibración que se obtiene a partir de la correlación entre la absorbancia de un patrón y la concentración de la sustancia a controlar.
En esta rama se utiliza la Regresión Lineal entre otros para ajustar la recta de Paris , una ecuación que sirve para estudiar elementos sometidos a fatiga en función del número de ciclos a los que se somete un material. La bondad del ajuste se comprueba representando el conjunto de valores discretos a-Nm obtenidos experimentalmente, frente a la curva correspondiente a la recta de Paris definida por los valores “C” y “m”.
En electricidad se puede obtener el valor de una resistencia en un circuito y su error mediante un ajuste de regresión lineal de pares de datos experimentales de voltaje e intensidad obtenidos mediante un voltímetro y un amperímetro.
Calibración de un sensor de temperatura (termopar) en función de la caída de tensión y la temperatura. Se estudia la forma en que varía la temperatura de un líquido al calentarlo. Se calibra el sensor y simultáneamente se mide la variación de temperaturas en un líquido para representar los datos obtenidos posteriormente mediante Regresión Lineal.
Determinación del coeficiente de rozamiento estático de forma experimental a partir de la medición del ángulo de inclinación de una rampa. Se realiza un montaje ajustando un circuito para medir el ángulo de inclinación, y se realizan mediciones variando dicho. Mediante la regresión lineal de los datos obtenidos, se obtiene la ecuación y el índice de correlación a fin de saber el error.
Dos de los parámetros más importantes de una soldadura es la intensidad aplicada al hilo y la velocidad de alimentación del mismo. Mediante técnicas de regresión lineal se elaboran las rectas que relacionan estos parámetros con la separación entre el hilo y la zona a soldar.
Con la metodología 2k es posible mejorar un proceso mediante la realización de experimentos, determinando qué variables tienen un efecto significativo. A partir de esas variables se obtiene una recta de regresión que modeliza el efecto. Por ejemplo se podría obtener la relación entre la temperatura y la presión en un proceso industrial.
Mediante técnicas de regresión lineal se caracterizarán diversas cualidades del hormigón. A partir del módulo de elasticidad es posible predecir la resistencia a la compresión de una determinada composición de un hormigón. También se puede determinar la succión capilar a partir del volumen absorbido por una muestra y el tiempo que ha durado la succión.
Ejemplo en JavaScript para regresión lineal:
Ejemplo de una rutina que utiliza una recta de regresión lineal para proyectar un valor futuro: Código escrito en PHP
Es también posible entrenar un regresor lineal en Python, utilizando la librería sklearn:
En la práctica, con mucha frecuencia es necesario resolver problemas que implican conjuntos de variables, cuando se sabe que existe alguna relación inherente entre ellas. Por ejemplo, en un caso industrial se puede saber que la pintura, para partes automotrices, está relacionada con la cantidad de pigmentación con la que se lleva a cabo. Puede ser interesante desarrollar un método de predicción, esto, un procedimiento para estimar el contenido de pigmentación que deben de tener las pinturas para cumplir con las especificaciones de las armadoras como se muestra en la siguiente imagen de tal manera que el problema consiste en lograr la mejor estimación de la relación entre las variables.

Del ejemplo citado anteriormente, los gramos de pigmentación son la variable independiente y la resolución de pintura es la respuesta “Y”
El término regresión lineal implica “Y” esta linealmente relacionado con “X” por la ecuación de la recta:
Y=b+mX o Y=bx+c
La manera en que se representa el color en las armadoras y ensambladoras, es a través de la Figura 1, la cual muestra la combinación de todos los colores posibles.
Para nuestro análisis en cuestión el color se especifica cómo se muestra en la Tabla 1. Las especificaciones de color para los volantes de un modelo de automóvil, son las siguientes:
De esta manera se observa que las especificaciones son muy justas y cualquier ajuste equivoco de pigmentación en la pintura ocasionará, material en condiciones NG, proporcionando indicadores negativos a la empresa como pérdida de tiempo, dinero, aumento de scrap así como sus indicadores de PPMS internos y con su cliente. Haciendo una corrida amplia y manipulando el pigmento blanco se toma de lecturas de las condiciones de la pintura. Son conforme a la Tabla 2.
Estimando el valor de la pendiente “β1” (que llamaremos b) y el valor “β0” (que llamaremos a), se tiene que:
La pendiente de la recta estimada es:
El valor de “β0” estimados es:
De tal manera que la fórmula de la recta estimada para el ejemplo de la pintura es:
Y la gráfica para validar la normalidad de los errores (uno de los supuestos en los que se basa este análisis) es:

Figura 2. Gráfica de probabilidad.
De esta manera, la función de la recta a través de los mínimos cuadrados funciona e interactúa para generar una ayuda en el ámbito industrial y generar un valor probabilístico en beneficio de obtención de una similitud de operaciones.
Este método ayudara a las empresas a: • Reducción de tiempos en decisiones de procesos • Reducción de inversión de materiales en los procesos. • Generar un valor mínimo de incertidumbre en los procesos • Estandariza procesos.
La función de la recta es aplicable en el ámbito industrial al generar una regresión lineal para la obtención de un valor esperado que ayude a las compañías a tener una idea de un valor de una variable que pueden controlar en beneficio de sus procesos.
El rendimiento de una reacción química depende de la temperatura de operación y de la concentración inicial del reactivo. Efectué un análisis de regresión a los siguientes datos:
SOLUCIÓN
Aplicando las fórmulas citadas anteriormente obtendremos los resultados de todos los datos que serán necesarios para el cálculo de la Tabla ANOVA.
En primer lugar se ajustara el modelo lineal y= β0 + β 1x1+ β 2x2+ε a los datos, se realizará la estimación de los coeficientes, y obtendremos la varianza residual:
S2 =1,04881
Tras esto a partir de los residuos calculados y representados en una tabla se calcula el coeficiente de determinación:
R2 =0,959559
Por último se calculan las varianzas asociadas a cada uno de los estimadores de los parámetros:
Tras esto ya podemos calcular y representar los resultados en la Tabla ANOVA. La significación global del ajuste se presenta en la Tabla E52.3:

Al comparar Fo con el F0.05, 2, 5 puede concluirse que el modelo es significativo y que al menos un bi es distinto de cero. La significancia del efecto de cada Xi se probara a partir de la prueba 1, basada en una prueba “t”, dicho análisis se presenta a continuación:

Al comparar el to asociado a cada bi con la t0.025,5 puede observarse que los efectos tanto de la temperatura como de la concentración son significativos a un nivel de confianza del 95%. El modelo ajustado es por tanto:
Y = 39.75 + 3.0 . X concentración + 0.25 . X temperatura
La validación del modelo se haría en base al análisis de los residuos, a través de los siguientes gráficos:
Un análisis de los gráficos de los residuos contra las variables concentración y temperatura permitirá concluir si el factor concentración presenta un efecto muy importante sobre la variabilidad del rendimiento, en función de si una mayor concentración reduce la variabilidad en cuanto al rendimiento de la reacción química.
Escribe un comentario o lo que quieras sobre Regresión lineal (directo, no tienes que registrarte)
Comentarios
(de más nuevos a más antiguos)
Aún no hay comentarios, ¡deja el primero!