Distribución uniforme continua
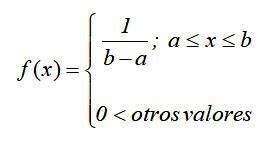
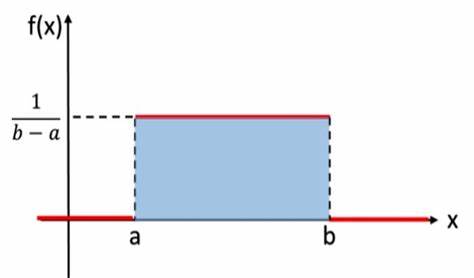
En teoría de probabilidad y estadística, la distribución uniforme continua es una familia de distribuciones de probabilidad para variables aleatorias continuas, tales que para cada miembro de la familia, todos los intervalos de igual longitud en la distribución en su rango son igualmente probables. El dominio está definido por dos parámetros, y , que son sus valores mínimo y máximo respectivamente.


Si es una variable aleatoria continua con distribución uniforme continua entonces escribiremos o .



Si entonces la función de densidad es:
para .
![{displaystyle xin [a,b]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/026357b404ee584c475579fb2302a4e9881b8cce)
Si entonces a función de distribución es:

la cual es fácil de obtener a partir de la función de densidad pues
Si es una variable aleatoria tal que entonces la variable aleatoria satisface algunas propiedades.
La media de la variable aleatoria es
Esta se demuestra fácilmente utilizando la definición de esperanza matemática
Si uno grafica la función de densidad de esta distribución notará que la media corresponde al punto medio del intervalo .
![[a,b]](https://wikimedia.org/api/rest_v1/media/math/render/svg/9c4b788fc5c637e26ee98b45f89a5c08c85f7935)
La varianza de la variable aleatoria es

El -ésimo momento de la variable aleatoria está dado por

para .

La función generadora de momentos de esta distribución es
para valores .

Esta distribución puede ser generalizada a conjuntos de intervalos más complicados. Si es un conjunto de Borel de medida finita positiva, la distribución probabilidad uniforme en se puede especificar definiendo que la pdf sea nula fuera de e igual a 1/K dentro de , donde K es la medida de Lebesgue de .

Sea una muestra independiente e identicamente distribuidas de . Sea el -ésimo estadístico de orden de esta muestra. Entonces la distribución de probabilidad de es una distribución Beta con parámetros y . La esperanza matemática es






Esto es útil cuando se realizan Q-Q plots.
Las varianzas son
La probabilidad de que una variable aleatoria uniformemente distribuida se encuentre dentro de algún intervalo de longitud finita es independiente de la ubicación del intervalo (aunque sí depende del tamaño del intervalo), siempre que el intervalo esté contenido en el dominio de la distribución.
Es posible verificar esto, por ejemplo si y es un subintervalo de con fijo y , entonces

![{displaystyle [x,x+d]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a293b4e8d117d52f96d3ecaacd9a63a6ff1dea0c)


![Pleft(Xinleft [ x,x+d
ight ]
ight)
= int_{x}^{x+d} frac{mathrm{d}y}{b-a},
= frac{d}{b-a} ,!](https://wikimedia.org/api/rest_v1/media/math/render/svg/340d0dbad9f439585a005637a3ac06a4d6214f1f)
lo cual es independiente de . Este hecho es el que le da su nombre a la distribución.


Si se restringe y entonces la distribución resultante se llama distribución uniforme estándar. Si es una variable aleatoria con distribución uniforme estándar entonces se escribirá .



Para esta distribución en particular, se tiene que:
La función de densidad para cualquier valor es simplemente la constante , esto es
![{displaystyle xin [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/64a15936df283add394ab909aa7a5e24e7fb6bb2)

La función de probabilidad de se reduce a la recta identidad, esto es
para valores de
La media y varianza están dadas por

respectivamente.
Una propiedad interesante de la distribución uniforme estándar es que si una variable aleatoria entonces .

Si tiene una distribución uniforme estándar, es decir, entonces:
Siempre y cuando se sigan las mismas convenciones en los puntos de transición, la función densidad de probabilidad puede también ser expresada mediante la función escalón de Heaviside:
No existe ambigüedad en el punto de transición de la función signo. Utilizando la convención de la mitad del máximo en los puntos de transición, la distribución uniforme se puede expresar a partir de la función signo como:
En estadística, cuando se utiliza un p-valor a modo de prueba estadística para una hipótesis nula simple, y la distribución de la prueba estadística es continua, entonces la prueba estadística esta uniformemente distribuida entre 0 y 1 si la hipótesis nula es verdadera.
Existen muchos usos en que es útil realizar experimentos de simulación. Muchos lenguajes de programación poseen la capacidad de generar números pseudo-aleatorios que están distribuidos de acuerdo a una distribución uniforme estándar.
Si u es un valor muestreado de una distribución uniforme estándar, entonces el valor a + (b − a)u posee una distribución uniforme parametrizada por a y b, como se describió previamente.
La distribución uniforme resulta útil para muestrear distribuciones arbitrarias. Un método general es el método de muestreo de transformación inversa, que utiliza la distribución de probabilidad (CDF) de la variable aleatoria objetivo. Este método es muy útil en trabajos teóricos. Dado que las simulaciones que utilizan este método requieren invertir la CDF de la variable objetivo, se han diseñado métodos alternativos para aquellos casos donde no se conoce el CDF en una forma cerrada. Otro método similar es el rejection sampling.
La distribución normal es un ejemplo importante en el que el método de la transformada inversa no es eficiente. Sin embargo, existe un método exacto, la transformación de Box-Muller, que utiliza la transformada inversa para convertir dos variables aleatorias uniformes independientes en dos variables aleatorias independientes distribuidas normalmente.
Escribe un comentario o lo que quieras sobre Distribución uniforme continua (directo, no tienes que registrarte)
Comentarios
(de más nuevos a más antiguos)
Aún no hay comentarios, ¡deja el primero!